Bitwise Exact Rl
Bitwise-exact Batch Invariant On-Policy Reinforcement Learning with vLLM and TorchTitan
In the septillions of flops used to pre-train models, this mismatch between values has largely been avoidable. Pre-training typically runs at a fixed batch size which induces the same reduction kernels to be run - often side-stepping the issue entirely.
Reinforcement learning, on the other hand, seems to almost exclusively run different reduction algorithms due to its inference-heavy (and thus largely latency and memory-bound) nature. Kernels optimized for low-batch size inference typically run reductions all at once, whereas kernels for training models parallelize heavily to reuse data and amp up compute utilization. That means the generators and the trainers are typically running completely different kernels!
So intuitively, why might this be an issue? A rudimentary explanation is that the training becomes implicitly “off-policy” because the outputs from the generator do not match the outputs a trainer might produce given the same inputs.
Discussion on this can be found on ThinkingMachine’s post Defeating Nondeterminism in LLM Inference (He et al.) and the post Your Efficient RL Framework Secretly Brings You Off-Policy RL Training (Yao, Liu et al.).
Background
Floating point numbers are effectively a binary scientific notation. They utilize three components: a sign bit (s), a mantissa (M) and an exponent (e).
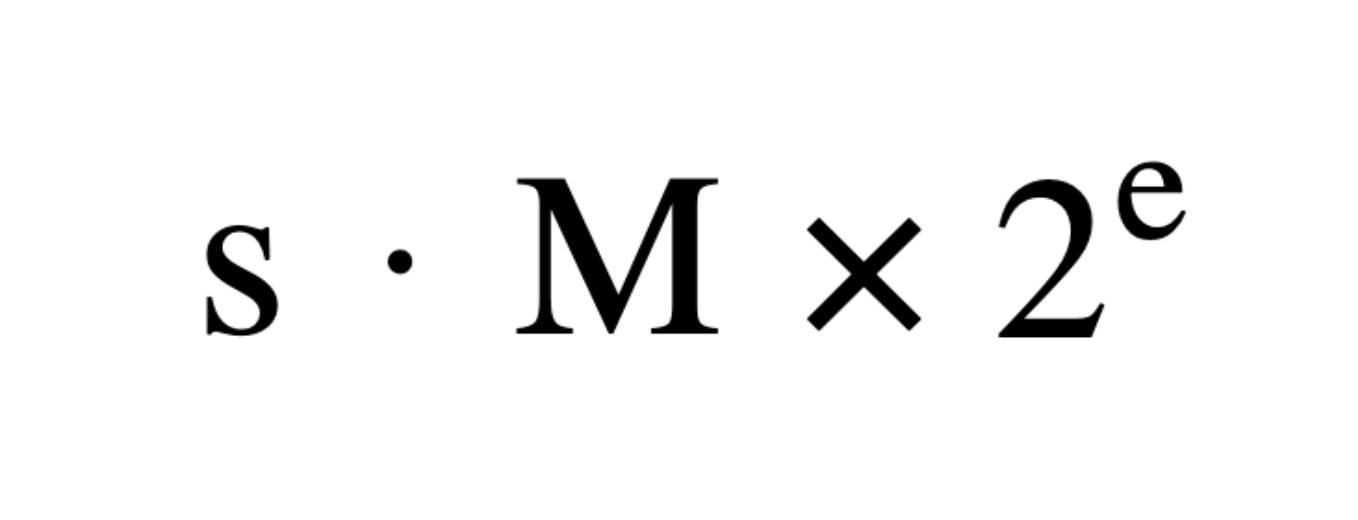
Each of these components are represented as integers and suffer from the exact same rounding errors you might expect. In bf16, the most commonly used representation for machine learning, 7 bits are dedicated to the mantissa. This is not very many bits! The value 3.0 can be represented exactly, but a value like 3.6 cannot…
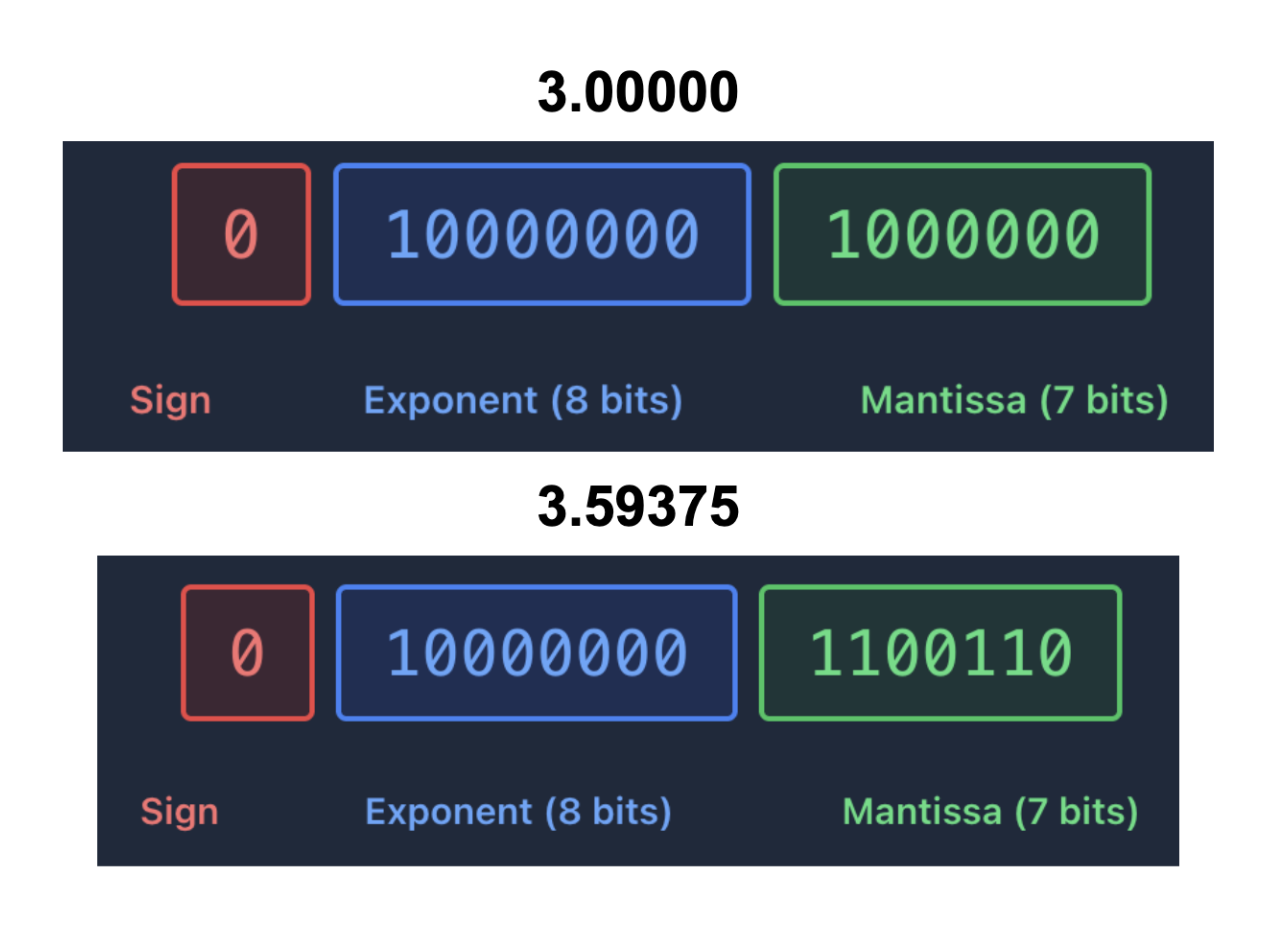
When you want a new value in bf16 you end up rounding it to the nearest available value. What’s of particular interest today is the implication of this rounding process happening at different points in a sequence of additions.
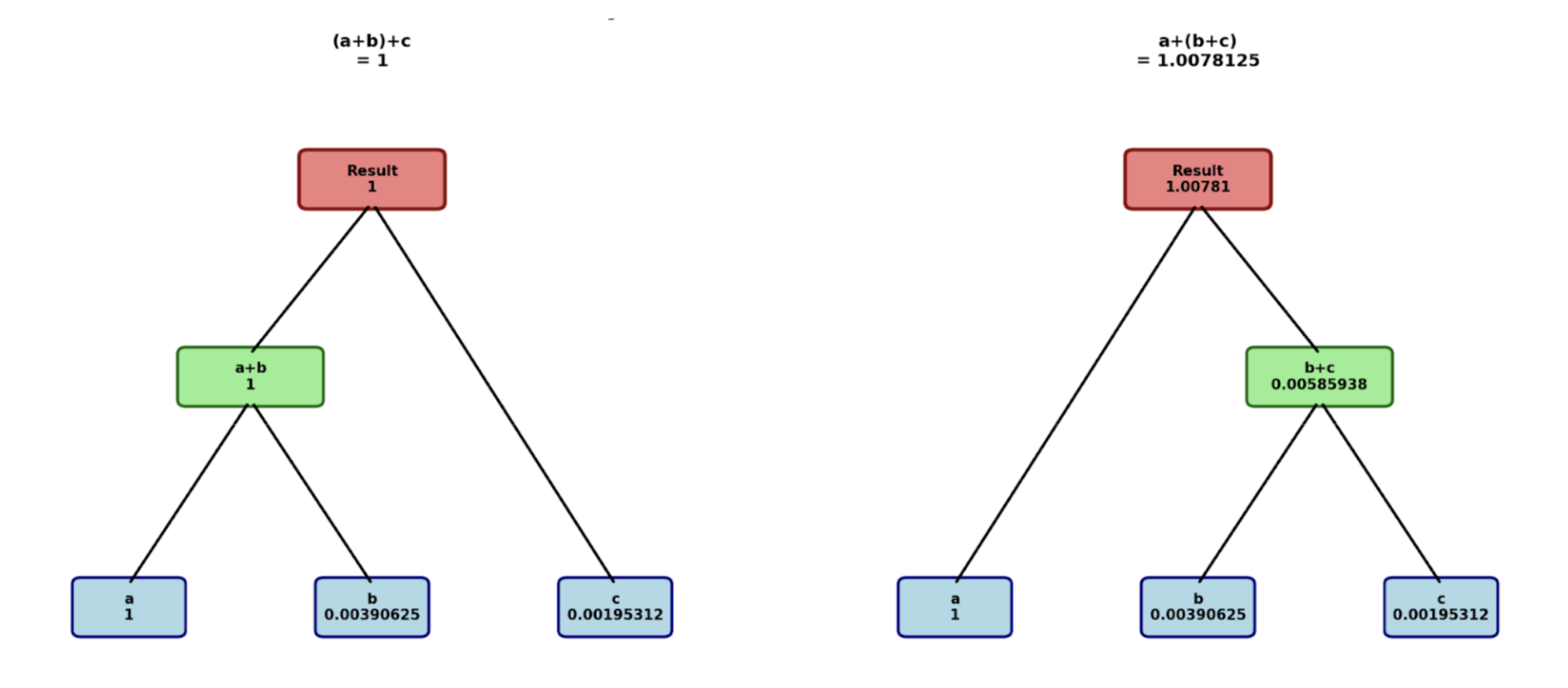
These rounding steps can cause two of the exact same inputs to generate different outputs! That means the same framework on the same hardware with the same inputs and the same weights can produce distinct outputs if any of the logic anywhere in the execution dispatches a different (but still correct) kernel.
Demonstration
Reinforcement learning has been shown to amplify tiny numerical perturbations, leading to non-deterministic and unstable training behavior. By combining the recent work of vLLM with TorchTitan we were able to demonstrate the stabilized training dynamics of reinforcement learning with exact bitwise parity between generator and trainer. This has been landed as a script in TorchTitan here.
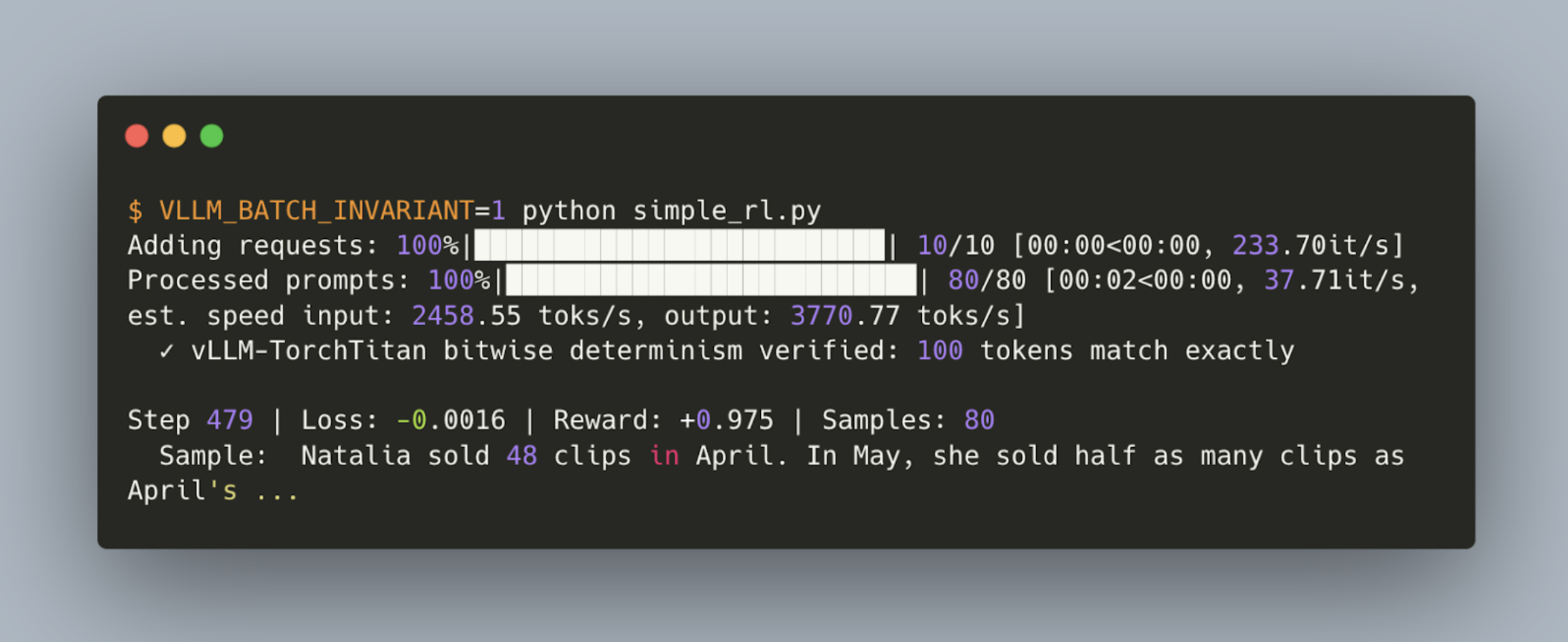
The script will download and run an RL fine-tune of Qwen3 1.7B locally and plot the reward and entropy in tensorboard.
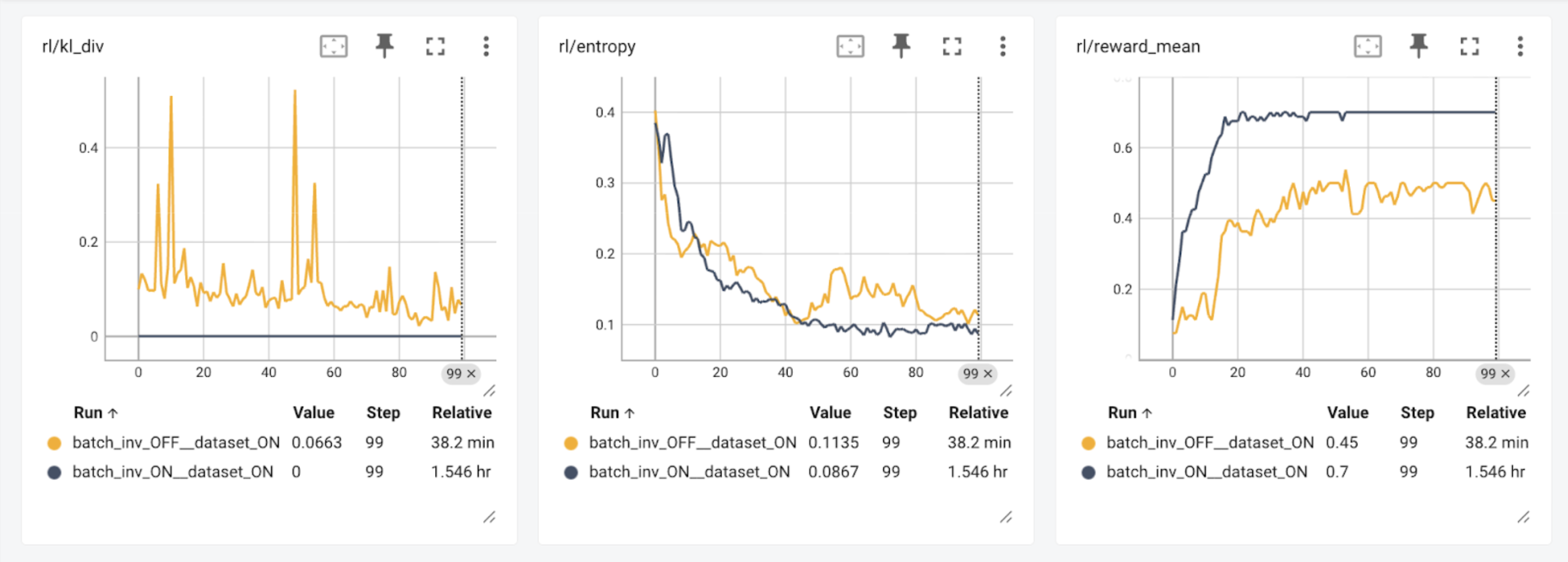
Running the demonstration associated with this blog post we see exactly the issue described below. Running the generator with different kernels than the trainer (batch_inv_OFF) shows a reduced reward over 100 steps. Enabling bitwise exact training, we see the model not only train in fewer steps, but reach a higher total reward!
How It’s Done & What’s Next
We tackled not only invariance in the same framework, but across two different frameworks. This was a challenging task as it required effectively auditing every single invocation of every kernel. We heavily leveraged the forward pass kernels from vLLM’s recent batch invariance work and wrote simple backward passes for these.
Then, we wrote a generic reinforcement learning script using GSM8K and a correctness reward. We run everything synchronously, alternating between trainer and generator on a single host. This is demonstrative of exactly on-policy execution, but is not very common in large scale runs.
While building this, testing was straightforward as we are able to use exact bitwise checks to ensure the forward logprobs and the perplexity generated by the trainer are identical. We will continue to improve the performance of vLLM and simplify the integration to support all TorchTitan models. To follow this work, please see the linked RFC: #28326.
Acknowledgements Bram Wasti, Teja Rao, Paul Zhang, Tianyu Liu, Zhuohan Li, Natalia Gimelshein